In een datacenter is (vrijwel) altijd behoefte aan een laag-twee-netwerk dat het hele datacenter omspant. Het Spanning Tree protocol vormt de basis alle laag-twee-netwerken, maar alleen omdat er (nog) geen andere mogelijkheid is.
Voor datacenter-netwerken wordt gekeken naar alternatieven voor Spanning Tree, zoals bijvoorbeeld FabricPath, Dynamic Fabric Automation of TRILL. Voor al deze protocollen geldt:
– Ze zijn bedacht om laag-twee connectiviteit te bieden in een groot, plat netwerk, zonder paden die geblokkeerd zijn en met meer stabiliteit dan Spanning Tree.
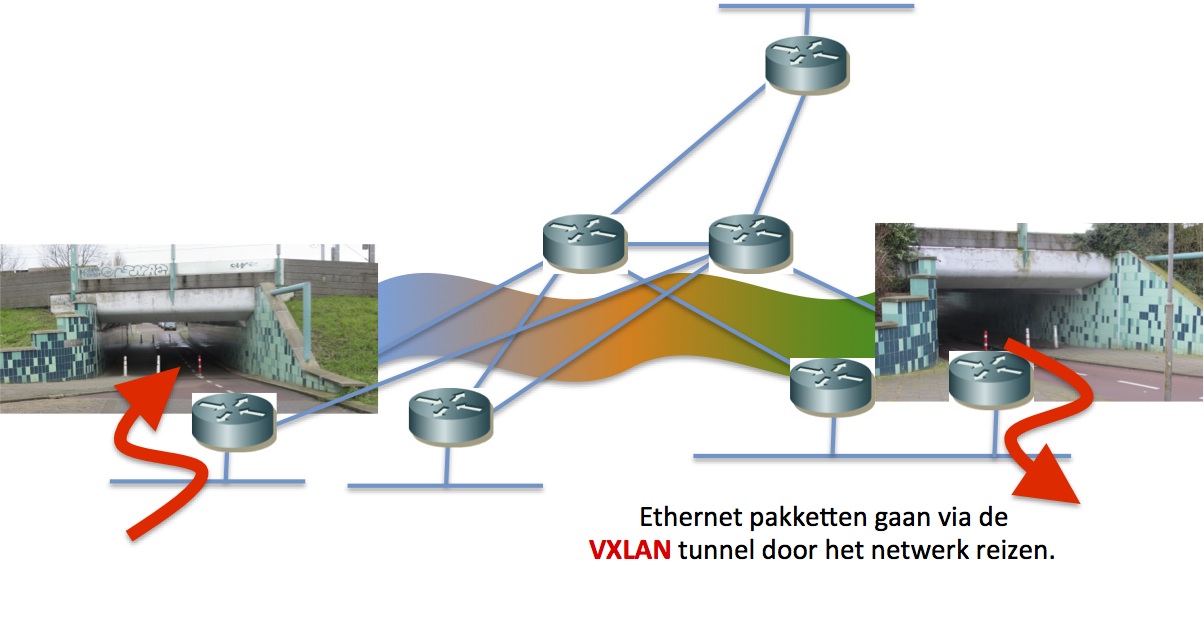
– Dit gebeurt steeds door een extra header te plakken voor het oorspronkelijke Ethernet-pakket, welke het pakket ‘routeerbaar’ maakt. ‘Routeerbaar’ wil zeggen: aan de hand van deze extra header kan iedere switch in het netwerk bepalen waar het pakker afgeleverd moet worden.
– Ze hebben gemeen dat ze IS-IS gebruiken als routeringsprotocol om de topologie van het netwerk te ontdekken en te adverteren.
Een vraag die men regelmatig hoort is: Waarom IS-IS? In enterprise netwerken is IS-IS zo ongeveer het minst gebruikte routeringsprotocol. Het is onbekend en dus onbemind en het heeft een imago van ‘het is in gebruik bij service providers, dus het zal wel ingewikkeld zijn.’
Dus: waarom IS-IS? Wel , laten we de alternatieven bekijken.
– Men had een heel nieuw protocol kunnen ontwikkelen om Spanning Tree te vervangen… Dat had gekund maar dat zou jaren overleg hebben gevergd, gevolgd door testen en het daarna uitbrengen van versies twee en drie voor er een stabiele versie zou zijn. Waarschijnlijk was er dan nu nog geen vervangend protocol geweest.
Er bestaan vele routing-protocollen om de topologie van een netwerk in kaart te brengen, de meest gebruikte in enterprise-netwerken zijn EIGRP en OSPF. Men zou verwachten dat voor een vervanger van Spanning Tree in het enterprise datacenter een van deze twee gekozen zou worden.
– EIGRP is heel sterk in het afhandelen van grote hub-en-spoke netwerken met veel noord-zuid verkeer. EIGRP is heel schaalbaar als adressen in eeen hiërarchische netwerk kunnen worden geaggregeerd… Echter, in het datacenter is heel veel oost-west verkeer en is behoefte aan platte netwerken waar virtuele machines vrij heen en weer geplaatst kunnen worden maar met gevolg dat geen adressen geaggregeerd kunnen worden.
– OSPF schaalt door een netwerk op te splitsen in een backbone area met daaraan vast andere area’s. Iedere area moet in principe een aaneengesloten deel van het netwerk zijn. Nu past een aaneengesloten backbone niet zo goed op het moderne datacenter design met leafs en onderling onafhankelijke spines en ook sluiten van elkaar gescheiden area’s niet goed aan bij het idee dat virtuele machines vrij moeten kunnen bewegen in het data center.
Verder geldt voor zowel OSPF als voor EIGRP: ze zorgen voor de uitwisseling van informatie over IP-adressen. Dat is voor een routeringsprotocol normaal, maar in een datacenter moet ook MAC-adres informatie uitgewisseld worden en in een datacenter moet de mogelijkheid zijn om broadcasts en niet-IP-multicasts te versturen… Daar is binnen de bestaande definities van OSPF of EIGRP niet in voorzien.
Dan het IS-IS protocol: het IS-IS protocol werkt net als OSPF met een shortest path first algoritme. Echter, terwijl OSPF bij een verandering binnen een area altijd een complete herberekening van het algoritme maakt, kent IS-IS een zogenaamde ‘partial route calculation’: in de situatie waarin wel de adressen, maar niet de topologie verandert, wordt alleen een gedeelte van de berekening overgedaan. En dat is heel mooi in een datacenter, waar – als virtuele machines verplaatst worden – wel de adressen veranderen, maar niet de topologie.
In de praktijk is gebleken dat in netwerken met enkele honderden routers in één enkele area het IS-IS protocol geen performance probleem heeft, terwijl in zo’n netwerk voor OSPF allang een opsplitsing in meerdere area’s aan te raden is. Vertaald naar datacenters: IS-IS kan een groot datacenter met honderden switches probleemloos als één area behandelen.
Nog een puntje in het voordeel van IS-IS is dat alle informatie in de IS-IS-pakketten expliciet gelabeld is: voor ieder veld in een pakket staat een label dat het type informatie en de lengte aangeeft. Deze flexibiliteit maakt het mogelijk om binnen de standaard extra labels te definiëren zodat ook andere gegevens tussen de switches uit kunnen worden gewisseld, zoals – voor het datacenter belangrijk – informatie hoe broadcasts en multicasts rondgestuurd moeten worden.
Samengevat:
Het IS-IS protocol schaalt probleemloos naar honderden switches in een plat netwerk, zodat virtuele machines probleemloos verplaatst kunnen worden en oost-west verkeer optimaal afgehandeld kan worden.
Het IS-IS protocol is flexibel in het doorgeven van andere informatie dan alleen IP-adressen, zodat in een datacenter alles wat nodig is voor laag-twee connectiviteit moeiteloos ingepast kan worden.
Kortom, ideaal voor de nieuwe laag-twee-protocollen voor het datacenters….
Filed under: Algemeen, DataCenter | Tagged: DFA, Fabricpath | 1 Comment »





 Ontdek de
Ontdek de

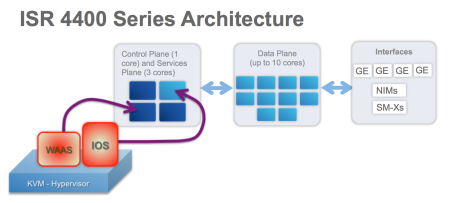
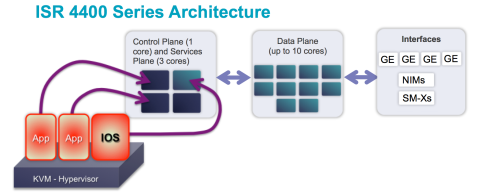

















 CiscoNL – Technology
CiscoNL – Technology Twitter
Twitter Youtube kanaal cisconltechnology
Youtube kanaal cisconltechnology